utstatusmirroring
The default interval for fetching the current state from Cribl Stream is set to 300s. Adapt inputs.conf if this interval needs to be adapted.
Sources & Destination
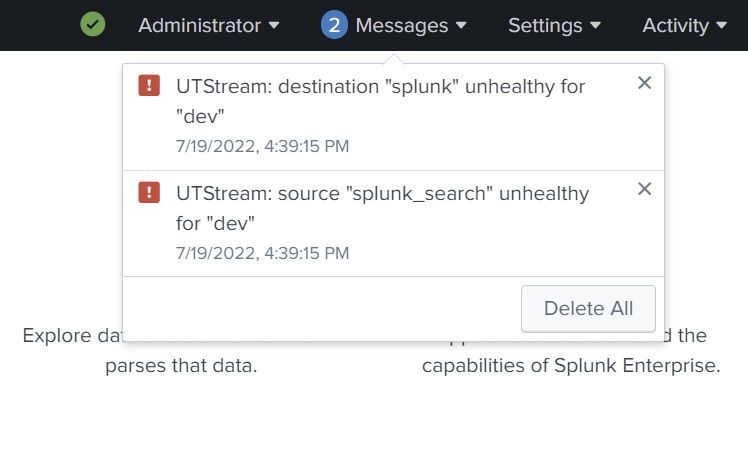
UTStream starts monitoring the health of sources and destinations as soon as a Cribl Stream instance is configured. Based on the state of the source or destination, a Bulletin Message is shown to users with applicable role.
If a source or destination is healed in Cribl Stream, the message gets removed. A message, that is removed by a user before the issue was fixed will be recreated.
Worker Nodes
The currently supported Cribl Stream versions do not provide a method to track worker nodes assigned to a worker group in Cribl Stream. To still get a notification if a worker node is no longer active in a worker group, a best-effort monitoring is implemented in UTStream.
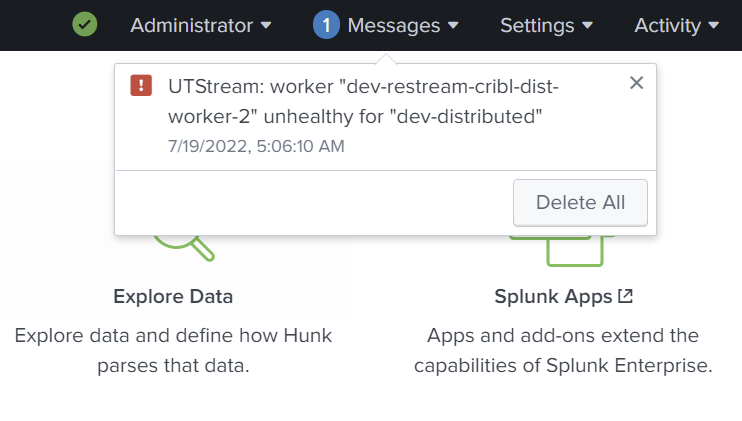
The monitoring works as follows:
utstatusmirroringqueries all worker nodes for the configured worker grouputstatusmirroringcompares the list of returned workers with a list saved inside Splunk- If a host fetched from Cribl Stream is not present in the list of Splunk → add host to list
- If a host in the list of Splunk was not fetched → create a message in the Bulletin Board and remove the host from the list
This monitoring poses the following issues:
- Worker Nodes that were never only while
utstatusmirroringwill not be notified - A message that was removed by a user will not be recreated if the host is still down
- If a host is decommissioned, a message will be shown even if
downis expected